
This is part of an ongoing series of post by Grant as he takes his vast knowledge of SQL Server and applies it to adding PostgreSQL and shares it with you so you can skip learn from his triumphs and mistakes. For more you can go to the Learning PostgreSQL with Grant series home page
You have an instance of PostgreSQL running locally (or you’re connected to the cloud). Now, what to do with it? In the first article in this series, I said I would start by learning about backups. However, I realized I had another thing I needed to do before I could begin learning – and teaching — backups. I needed to create a database and a couple of tables. I could then back them up.
As with any data management system, there are many ways to get this done. You can do everything from a command line or use a graphical user interface (GUI) that lets you work with PostgreSQL. Finally, the SQL commands are available once you’re connected to PostgreSQL. I’m going to focus there, working primarily within Azure Data Studio (ADS). I’m doing this because:
- I like Azure Data Studio. I find it easy to work within. It’s fast. It’s clean. It has plugins to do all sorts of things
- For example, it plugs in very nicely to GitHub, so you can easily keep the code as you develop it up on GitHub (go here if you want to see my VERY basic PostgreSQL code: )
- I’m old, and I’m just more comfortable working on code within a dedicated coding tool as opposed to simply running it from the command line.
- I don’t want to document every single possible method, so I had to pick one. This is it.
That said, let’s get started.
CREATE DATABASE
The command to create a database is quite simple:
|
1 |
CREATE DATABASE postgrelearning; |
Well, that was easy.
Let’s talk about this just a little bit. Since I know SQL Server, I’m going to compare what’s going on here, to what’s going on there. In SQL Server, you have a system database called model used as a template when you create a new database. In PostgreSQL, the same thing happens, but the database is called template1. The table template1 operates very similarly to model. You can add objects to template1, and then they will automatically exist in any other new database you create.
However, there’s more going on in PostgreSQL. Let’s look at my list of databases:
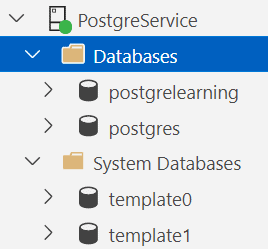
There’s also a template0 database. What’s that? Well, in the event you completely mess up template1, template0 acts as a baseline. Also, when you restore a database, PostgreSQL uses template0 to start that process (I’ll explain how and why once I learn).
And what about that postgres database? Well, that’s a default built into PostgreSQL so that tools always connect to a default database.
The CREATE DATABASE command has a number of options, as you can see in the documentation. One of the more interesting to me relates right back to those template databases. You can run the CREATE DATABASE command like this:
|
1 |
CREATE DATABASE templatetest WITH template = postgrelearning; |
That’s right. You can specify another database as a template. However:

You can only use a database as a template when there are no connections to that database at all.
There are several other options, from defining the database owner, its locale and collation, and more. I’m not going to cover them all now.
If you need to get rid of a database, the command again is simple:
|
1 |
DROP DATABASE templatetest; |
That will remove the entire database. However, you can’t have a connection to it when you drop the database. As with CREATE, DROP includes some options. For example, you could write the command like this:
|
1 |
DROP DATABASE IF EXISTS templatetest; |
That will eliminate an error if you try to drop a database that isn’t there. Also, you can delete a database that is in use:
|
1 |
DROP DATABASE IF EXISTS templatetest WITH (FORCE); |
Now, that’s dangerous, of course. Always exercise extreme caution using this command. In fact, I’d shy away from using it because all it takes is one slip-up, and you’ve dropped the production database.
One more thing. Using ADS, you can quickly and easily switch between databases in the query window. However, there doesn’t seem to be a way to do this strictly from SQL. You control the connection with the tool you are using.
CREATE TABLE
With a database in place, to have something to work with, start by using the CREATE TABLE syntax to get a table in place. If you’re already familiar with an RDBMS, you know that this is a positively huge topic (heck, follow the link and look at the documentation). I’m going to keep it simple for the moment and not go too far down the rabbit hole. There will be plenty to expand on later as we work through this series.
Here’s the first test:
|
1 2 3 4 |
CREATE TABLE TableTest1 (ID int NOT NULL, SomeValue varchar(50) NOT NULL, AnotherValue varchar(30) NULL); |
The core syntax is recognizable if you’re coming from SQL Server. The results look like this in ADS:
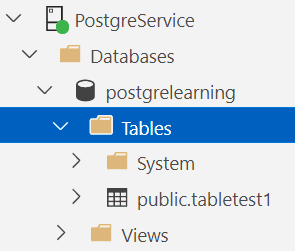
The code doesn’t include the schema, so the default schema, public, was used. I much prefer to define a schema and then assign tables to that rather than run the default. Having everything in a defined schema or schemas makes it much easier when it comes time to begin to lock things down.
Of course, to really create tables for testing, the example will need to be a bit more sophisticated than the above test. Let’s start with the schema:
|
1 |
CREATE SCHEMA hsr; |
From there, create a couple of tables with primary keys and foreign keys:
|
1 2 3 4 5 6 7 |
CREATE TABLE hsr.radiobrand (radiobrandid int PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, radiobranddesc varchar(50) NOT NULL); CREATE TABLE hsr.radio (radioid int PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, radioname varchar(50) NOT NULL, radiobrandid int REFERENCES hsr.RadioBrand NOT NULL); |
As with SQL Server, there’s syntax to support creating the keys using ALTER as well as CREATE. There’s also syntax for creating a table constraint, which, if you were creating a compound key or consuming one as a foreign key, you’d have to use instead. You could create the hsr.radio table this way:
|
1 2 3 4 5 6 |
CREATE TABLE hsr.radio (radioid int NOT NULL GENERATED BY DEFAULT AS IDENTITY, radioname varchar(50) NOT NULL, radiobrandid int NOT NULL, CONSTRAINT radiopk PRIMARY KEY (radioid), FOREIGN KEY (radiobrandid) REFERENCES hsr.RadioBrand(radiobrandid)); |
The IDENTITY definition on the column must stay in place since it’s a column property. However, you could create the primary and foreign keys separately from the column definitions. For the sake of consistency, I’ll probably keep that second syntax instead of the first. That way, all the code looks the same, not just some constraints that have compound keys.
That’s the basics.
You can test it out just a little:
|
1 2 3 4 5 6 7 |
insert into hsr.radiobrand (radiobranddesc) VALUES ('Icom'); SELECT radiobrandid, radiobranddesc FROM hsr.radiobrand; |
The results are as follows:
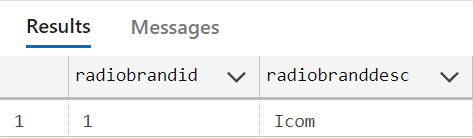
In short, all the basics are working.
Conclusion
We now have a database, a couple of tables, and some data. At its core, PostgreSQL is very much the same as SQL Server. Not identical, of course, but very similar. We’ll start to see more significant differences as we dive deeper. The ability to define more than one template database is a neat trick. The rest of the basics are what I’d expect.
Next time, we really are going to look into backup and restore.


Load comments